4.Django模板高级
模板介绍
在前面的几节中我们都有使用到模板,但是没有详细讲模板的使用,只是简单的展示数据。这节课我们将深入讲解django中的模板。
模板的设计实现了业务逻辑view与显示内容template的分离,一个视图可以使用任意一个模板,一个模板可以供多个视图使用
模板包含两部分:
- 静态部分,包含html、css、js
- 动态部分,就是模板语言
创建项目后,在“项目名称/settings.py”文件中定义了关于模板的配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
模板配置: BACKEND: 模板引擎,创建项目django默认配置,一般不需要动 DIRS: 模板的路径,需要开发者填写,一般定义在项目目录下的templates中。 APP_DIRS:告诉模板引擎是否应该进入每个已安装的应用中查找模板,设置为True表示进入。 OPTIONS: 定义如何传递上下文,创建项目django默认配置,一般不需要动
Django模板语言
1、变量
变量的值是来自context中的输出, 这类似于字典对象的keys到values的映射关系。 变量是被 括起来的部分
我是{{name}},{{slogan}}万岁。
如果使用一个 context包含 {'name': '盖伦', 'slogan': '德玛西亚'}, 这个模板渲染后的情况将是:
我是盖伦,德玛西亚万岁。
变量名必须由字母、数字、下划线(不能以下划线开头)和点组成 如果模板中遇到点,将会按照下面的顺序解析:
比如:
1.先将blog当作字典,blog['name'],如果没找到再利用第二种方式查找。
2.将blog当作对象,先属性后方法,查找属性name,如果没有再查找方法name()
3.如果是格式为blog.0则解析为列表blog[0]
示例: 在视图中创建一个视图:
def var(request):
uname = {"name":'盖伦'}
pwd = ['123456']
context = {'uname':uname,'pwd':pwd}
return render(request,'personal_blog/var.html',context=context)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
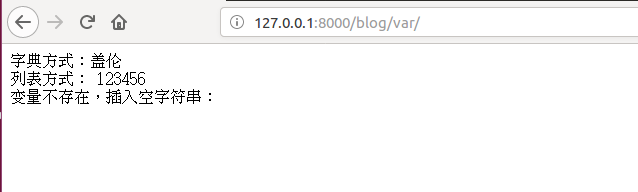
字典方式:{{ uname.name }}
<br>
列表方式: {{ pwd.0}}
<br>
变量不存在,插入空字符串:
{{ gailun }}
</body>
</html>
访问:http://127.0.0.1:8000/blog/var/
变量输出情况如下:
2、标签
标签在渲染的过程中提供任意的逻辑。 例如,一个标签可以输出内容,作为控制结构,例如“if”语句或“for”循环从数据库中提取内容,甚至可以访问其他的模板标签。 django内置标签 标签语法:
{% 代码段 %}
if标签语法结构:
{%if 条件1 %}
条件1成立渲染这段代码
{% else %}
条件1不成立渲染这段代码
{%endif%} #必须有结束标记
-------------------------------------
{%if 条件1 %}
条件1成立渲染这段代码
{%elif 条件2 %}
条件2成立渲染这段代码
{% else %}
条件不成立渲染这段代码
{%endif%} #必须有结束标记
for标签语法结构:
{% for foo in 列表%}
循环逻辑
{{forloop.counter}}表示当前是第几次循环,从1开始
{%empty%}
列表为空或不存在时执行此逻辑
{%endfor%}
#必须有结束标记 {% endfor%}
comment(多行注释)
{% comment %}
里面是注释内容
{% endcomment %}
单行注释
{# 注释内容 #}
比较运算符 运算符左右两侧不能紧挨变量或常量,必须有空格
==
!=
<
>
<=
>=
逻辑运算符
and
or
not
案例: 在personal_blog/views.py定义一个视图:
def tag(request):
cg = Category.objects.all() # 查询所有分类
return render(request,'personal_blog/tag.html',context={'category':cg})
创建一个模板 templates/tag.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
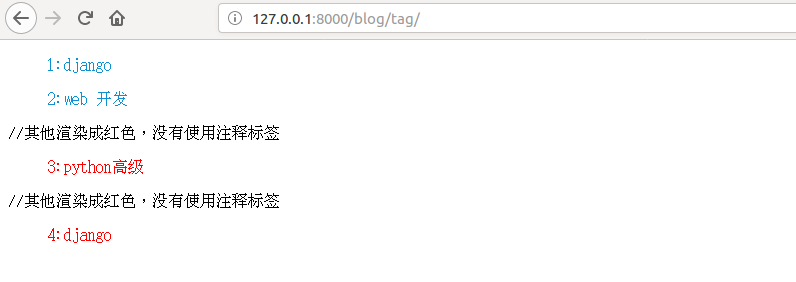
{% for foo in category %}
{% if foo.id <= 3 %}
{# 这里是注释:id小于等于3的分类名渲染成 蓝色#}
<ul style="color: #0e90d2">{{ forloop.counter }}:{{ foo.category_name }}
</ul>
{% else %}
//其他渲染成红色,没有使用注释标签
<ul style="color: red"> {{ forloop.counter }}:{{ foo.category_name }}</ul>
{% endif %}
{% empty %}
<span>不存在分类,当category 为空时会执行这里 </span>
{% endfor %}
{% comment %}
多行注释
{% if foo.id <= 3 %}
{# 这里是注释:id小于等于3的分类名渲染成 蓝色#}
<ul style="color: #0e90d2">{{ forloop.counter }}:{{ foo.category_name }}
</ul>
{% endcomment %}
</body>
</html>
配置url:
url(r'^tag/$', views.tag),
访问: http://127.0.0.1:8000/blog/tag/
条件逻辑判断都生效。
3、过滤器
在模板使用管道符号|来应用过滤器,用于进行计算、转换等操作,可以使用在变量、标签中。 如果过滤器需要参数,则使用冒号:传递参数
变量|过滤器:参数
常用过滤器: add: 把add后的参数加给变量 capfirst:首字母变大写 cut: 移除指定字符串 date: 根据给定格式对一个date变量格式化
日期date,用于对日期类型的值进行字符串格式化,常用的格式化字符如下 Y表示年,格式为4位,y表示两位的年 m表示月,格式为01,02,12等 j表示日,格式为1,2等 H表示时,24进制,h表示12进制的时 i表示分,为0-59 s表示秒,为0-59 A表示上午下午,ap/pm
default:如果value的计算结果为False,则使用给定的默认值
dictsort:接受一个字典列表,并返回按参数中给出的键排序后的列表
divisibleby:判断是否能被整除,能返回True
floatformat: 当变量值是浮点数时,指定保留几位小数,小数四舍五入。
join:用字符串拼接列表元素,相当于python中 str.jons(list)
length:返回长度,字符串,列表都可以
linebreaksbr:将文本中的换行符,转换成html中的换行符
lower:将字符串转换为全部小写
upper:将字符串转换为大写形式
random:返回给定列表中的随机项
title:使字符以大写字符开头,其余字符小写
truncatechars:如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾,对中文有效
slice:截取前几个字符,对中文有效
truncatewords:截取前几个字符,只对英文有效,对中文无效
add: 把add后的参数加给value,如果 value 为 4,则会输出 6. 过滤器首先会强制把两个值转换成Int类型。如果强制转换失败, 它会试图使用各种方式吧两个值相加。它会使用一些数据类型 (字符串, 列表, 等等.)
{{value|add:'2'}
{{ first|add:second }} first 是 [1, 2, 3] ,second 是 [4, 5, 6], 将会输出 [1, 2, 3, 4, 5, 6]
capfirst 首字母变大写
大写变量的第一个字母。如果第一个字符不是字母,该过滤器将不会生效。
例如:
{{ value|capfirst }}
如果 value 是 "django", 输出将变成 "Django".
cut 移除指定字符串 移除value中所有的与给出的变量相同的字符串 例如:
{{ value|cut:"a" }}
如果value为“hahahahah”,输出将为"hhhhh"。
date: 根据给定格式对一个date变量格式化
value|date:"Y年m月j日"
如果value是datetime对象 (例如,datetime.datetime.now()的结果),输出将是字符串 '2018年1月12日',当天日期。
dictsort 接受一个字典列表,并返回按参数中给出的键排序后的列表。
例如:
{{ value|dictsort:"age" }}
如果value为:
[
{'age':19,'name':'关羽'},
{'age':18,'name':'张飞'},
{'age':22,'name':'刘备'},
]
按照age排序
[{'age':18,'name':'张飞'},
{'age':19,'name':'关羽'},
{'age':22,'name':'刘备'},
]
divisibleby 如果value可以被给出的参数整除,则返回 True 例如:
{{ value|divisibleby:"2" }}
floatformat 保留几位小数 例如
{{ value|floatformat:3 }} # 保留三位小数
join:用字符串拼接列表元素,相当于python中 str.jons(list) 例如:
{{ value|join:"-" }}
如果value为 ['a','b'] 那么得到结果为 'a-b'
length 返回值的长度,这适用于字符串和列表。 例如:
{{ value|length }}
假如:value 为[1,2,3,'ds'] 返回4
lower:将字符串转换为全部小写 upper:将字符串转换为全部大写
{{value:lower}}
{{value:upper}}
title:使字符以大写字符开头,其余字符小写
{{value:title}} # 文本中的英文单词,首字母变大写
字符串截取:
truncatechars:如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾,对中文有效
{{value|truncatechars:'100' }}
slice:截取前几个字符,对中文有效
{{value|slice:'100' }}
truncatewords:截取前几个字符,只对英文有效,对中文无效
{{value|truncatewords:'100' }}
4、自定义过滤器
如果django自带的过滤器无法满足你的开发要求,django还支持自定义过滤器。
自定义的过滤器包含在某个应用中templatetags 包下,过滤器就是python中的函数,注册后就可以在模板中当作过滤器使用。
过滤器将放在templatetags包中的一个模块里,这个模块的名字是你稍后将要载入标签时使用的,所以要谨慎的选择名字以防与其他应用下的过滤器名字冲突。
在应用中创建一个名字叫templatetags的python包。
创建一个过滤器模块:
from django import template
register = template.Library()
为了成为一个可用的过滤器模块,这个模块必须包含一个名为 register的变量,它是template.Library 的一个实例,所有的标签和过滤器都是在其中注册的。所以过滤器模块需要包含上面两行代码。
自定义过滤器就是一个带有一个或两个参数的Python 函数: 第一个参数是:变量的值 第二个参数是:可选参数,接收调用者传递过来的参数
创建一个求余数的过滤器。
from django import template
register = template.Library()
@register.filter # 使用过滤器注册的方式,过滤器名为函数名
# @register.filter('mod') # 指定过滤器的名字为'mod'
def mod(value,arg=2): #过滤器第一个参数是模板变量,第二个参数是接收开发人员传过来的参数。
#自定义过滤器开发人员只能传一个参数。
# 创建一个求余数的函数,默认是求2的余数
return value % arg
# register.filter('mod',mod) # 方法注册,第一个参数是过滤器的名字,第二个参数是要注册的函数
在模板中调用自定义过滤器需要先加载过滤器模块如下使用 load标签:
在 templatetags 包中放多少个过滤器模块没有限制。只需要记住{% load %} 声明将会载入给定模块名中的过滤器。
{%load blog_extras%}
自定义过滤器应用到模板:
{%load blog_extras%}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{{ 5|mod }}
<br>
{{ 5|mod:3 }}
<br>
{{ 24|mod:3 }}
</body>
</html>
模板继承
1、模板继承
开发网站,一般都会有很多页面,大部分页面中都有相同的内容例如下图中的百度新闻网页头部内容都是相同的,那我们在模板中是不是需要写多份代码?
为了解决写重复代码:模板的继承
模板继承和类的继承含义是一样的,主要是为了提高代码重用,减轻开发人员的工作量 典型应用:网站的头部、尾部信息
模板继承中使用到两个标签: 父模板:
{% block 名称%}
父模板中预留区域,可以编写默认内容,如果子模板中重写了内容将被覆盖掉,如果子模板没有填充内容将使用父模板中编写的默认内容。
{% endblock 名称%}
子模板: extends标签 继承父模板,写在子模板的第一行。
{% extends "应用/父模板名称"%}
在子模板中可以不填充父模板留下的区域,那么将使用父模板中的默认内容。 填充父模板预留区域:
{% block 名称%} 这里的名称是父模板中预留区域时的名称。需要填充那块区域就填那个父模板预留区域的名称。
实际填充内容
{{block.super}} 用于获取父模板中block的内容,相当于类中的调用父类方法。
{% endblock 名称%}
2、模板继承案例
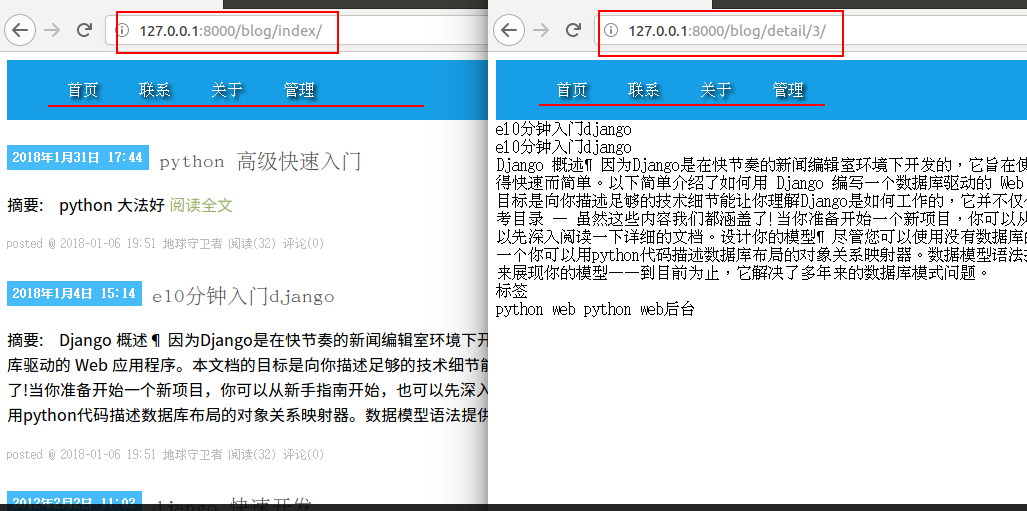
在我们的博客项目中,首页有菜单栏,现在我们利用继承关系,在详细页也加入菜单栏。

模板继承步骤: 1、观察每个网页内容,那么是重复需要提取出来的。 2、创建一个父模板,将提取的代码放到父模板中,并在父模板中预留子模板区域 3、在子模板中继承父模板,填充父模板留下的区域。
创建一个父模板 base.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
#navList {
width: 1200px;
margin: 0 auto;
height: 60px;
background-color: #169fe6;
}
#navList li {
float: left;
height: 60px;
line-height: 60px;
list-style-type: none;
}
#navList a {
padding: 0 20px;
font-size: 16px;
display: block;
cursor: pointer;
text-decoration: none;
color: #fff;
text-shadow: 3px 3px 3px #000;
}
#navList a:hover {
background: #fff;
}
</style>
{% block head %}
{% endblock head %}
</head>
<body>
<ul id="navList">
<li><a href="{% url 'index' %}">首页</a></li>
<li><a href="#">联系</a></li>
<li><a href="#">关于</a>
<li><a href="/admin/">管理</a></li>
</ul>
{% block body %}
{% endblock body %}
</body>
</html>
在index.html中继承父模板并填充父模板留下的区域。
{% extends 'personal_blog/base.html' %}
{% block head %}
<style>
.forFlow{
width: 1200px;
margin: 25px auto;
}
.dayTitle {
color: #fff;
background-color: #45bcf9;
padding: 6px 6px;
font-size: 12px;
display: block;
float: left;
margin-right: 10px;
}
.dayTitle a {
color: #fff;
text-decoration: none;
font-weight: bold;
}
.day .postTitle {
font-size: 21px;
line-height: 1.5em;
float: left;
clear: right;}
.day .postTitle a {
text-decoration: none;
color: #555;
}
.day .postTitle a:hover {
color: #0e90d2;
text-decoration: none;
}
.postCon {
font-family: 微软雅黑;
padding: 15px 0;
clear: both;
}
.postDesc {
clear: both;
color: #bcbcbc;
float: none;
text-align: left;
line-height: 200%;
font-size: 12px;
}
.readmore {
color: #9ab26b;
text-decoration: none;
}
</style>
{% endblock head %}
{% block body %}
{% for p in post_list %}
<div class="forFlow">
<div class="day">
<div class="dayTitle">
<a>{{p.created_time}}</a>
</div>
<div class="postTitle">
<a class="" href="{% url 'detail' p.id %}">{{p.title}}</a>
</div>
<div class="postCon">
<div class="c_b_p_desc">摘要: {{p.content|wordwrap:2}} {# |slice 过滤器,只取前100个字符 #}
<a href="{% url 'detail' p.id %}" class="readmore">阅读全文</a>
</div>
</div>
<div class="clear"></div>
<div class="postDesc">posted @ 2018-01-06 19:51 地球守卫者 阅读(32) 评论(0)</div>
</div>
</div>
{%endfor%}
{% endblock body %}
详细页 detail.html 继承父模板
{% extends 'personal_blog/base.html' %}
{% block head %}
<title>{{ post.title }}</title>
{% endblock head %}
{% block body %}
{{ post }}
<li>{{ post.title }}</li>
<span>{{ post.content }}</span>
<li>标签</li>
<li>
{% for tag in post.tags.all %}
<span>{{ tag }}</span>
{% endfor %}
</li>
</ul>
{% endblock body %}
模板提取继承完后访问首页,和详细页,都有菜单栏。
HTML转义
1、HTML转义
HTML转义:模板在接收到视图传过来的参数时会对一些符号进行转义。
小于号< 转换为<
大于号> 转换为>
单引号' 转换为'
双引号" 转换为 "
与符号& 转换为 &
如果你想要在视图中传一段html文本到模板,模板会自动将<>这些符号转义。模板渲染的时候将不会当标签渲染。
例如: 创建视图:
def zy(request):
html = '<h1>我很帅</h1>'
html2= '<i>我是真的很帅</i>'
context = {'h':html,'h2':html2}
return render(request,'personal_blog/zy.html',context=context)
创建模板zy.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{{ h }}
</body>
</html>
配置url
url(r'^zy/$', views.zy),
访问: http://127.0.0.1:8000/blog/zy/
可以看到模板并没有把视图传过去的\

2、关闭自动转义
如果想要从视图传html代码到模板中使用,需要关闭自动转义。
模板默认开启自动转义,关闭自动转义使用过滤器:
safe 关闭自动转义
{{value|safe}} # 变量value的内容将不转义。
escape 开启转义,如果使用了autoescape 标记某段代码不转义,但是刚好中间有那么一个变量需要转义,那么可以使用escape进行转义。
{{ value|escape }}
autoescape 标记一段代码区间内不转义
{%autoescape off%} off关闭,on开启
里面的代码不转义
{%endautoescape%}
关闭自动转义:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{#safe 关闭转义#}
{{ h|safe }}
{#autoescape 标签内的代码块关闭转义#}
{% autoescape off %}
{{ h }}<br>
{{ h2 }}
{% endautoescape %}
</body>
</html>
静态文件的处理
1、静态文件配置
网站中处理模板文件,网页应用一般需要提供其它必要的文件 —— 比如图片文件、JavaScript脚本和CSS样式表来为用户呈现出一个完整的网站。我们将这些文件称为“静态文件”。 为了方便管理一般会将静态文件放到一个单独的目录中。静态文件可以放在项目根目录下,也可以放在应用的目录下,由于有些静态文件在项目中是通用的,所以推荐放在项目的根目录下。 创建静态文件夹: 在项目目录下创建一个名字为 static的文件夹,在static下面再创建css,js,img 三个子文件夹,分别存放css文件,JavaScript文件,图片。 目录如下图:
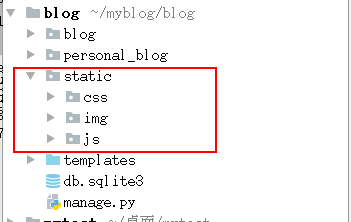
setting.py 中配置静态文件的查找路径。
STATIC_URL = '/static/' # 告诉django 请求以/static/开头的是静态文件
# 静态文件的搜索路径
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static'),
]
2、css样式引入
在写博客首页的时候由于没有学习静态文件的处理,所以我们的css样式都写在了模板中,现在知道静态文件应该放那里之后我们将css样式提取出来放到静态文件夹统一管理。
在static/css/文件夹下创建index.css文件并将模板中的css样式剪切过来。
css文件保存好后,在模板中引入进来,由于首页index.html继承了base.html,所以我们只需要在base.html中引入就可以了。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
{# 引入css文件 ,文件地址就是保存css文件路径,以/static/开头 #}
<link href="/static/css/index.css" rel="stylesheet" type="text/css">
{% block head %}
{% endblock head %}
</head>
.....
3、图片引入
一个网站图片是少不了的,一般我们将图片统一放在img目录下统一管理。
案例:给博客加个logo 将图片先保存到/static/img/目录下。 在base.html引入一张logo.png的图片
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link href="/static/css/index.css" rel="stylesheet" type="text/css">
{% block head %}
{% endblock head %}
</head>
<body>
<ul id="navList">
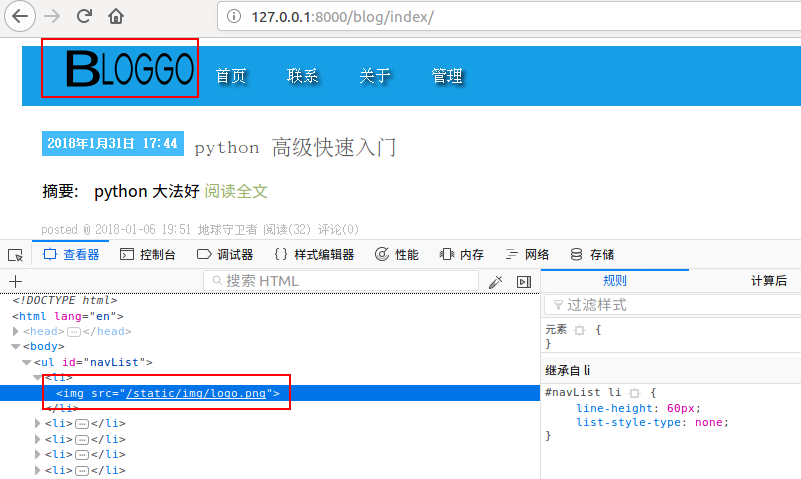
{# 用 html的img标签,src地址就是logo图片的路径,以/static/开头 #}
<li><img src="/static/img/logo.png"></li>
<li><a href="{% url 'index' %}">首页</a></li>
<li><a href="#">联系</a></li>
<li><a href="#">关于</a>
<li><a href="/admin/">管理</a></li>
</ul>
{% block body %}
{% endblock body %}
</body>
</html>
刷新首页:可以看到多了个图片,从网页源码中可以看到图片的url
4、JS文件引入
JavaScript文件的处理方式跟css文件的一样,不再演示,这里回忆下js文件如何在前端页面中引入
js引入语法:
<script src="static/js/jquery.js" type="text/javascript"></script>
六、图片上传
1、后台管理页面上传图片
要上传图片需要先按照PIL图片处理模块:
pip install Pillow==3.4.1
上传图片后,将图片存储在服务器硬盘上,然后将图片的路径存储在表中,一般大文件不会直接存数据库。 创建包含图片字段的模型类: 在blog项目下的post表中增加 image字段:
class Post(models.Model):
image = models.ImageField(upload_to='blog/')
# upload_to 表示图片保存的路径
由于修改了模型类需要重新生成迁移文件:
python manage.py makemigrations
执行迁移
python manage.py migrate
注意:如果数据库中已经有数据,并且有些字段不允许为空,可能会出现从新执行迁移失败问题。所以在设计模型类的时候,要考虑好有哪些字段避免开发过程再添加字段。
如果出现执行迁移失败的这里提供一个比较暴力的解决办法:
1、查看迁移生成的sql语句。
python manage.py sqlmigrate booktest 0001_initial #(booktest 应用名称,0001_initial生成的迁移文件名称) 查看执行迁移时的sql语句.
2、复制sql语句到数据库中执行,这样也能正确创建字段。
migrations目录下的文件就是迁移文件,最新一个就是最后生成的迁移文件。
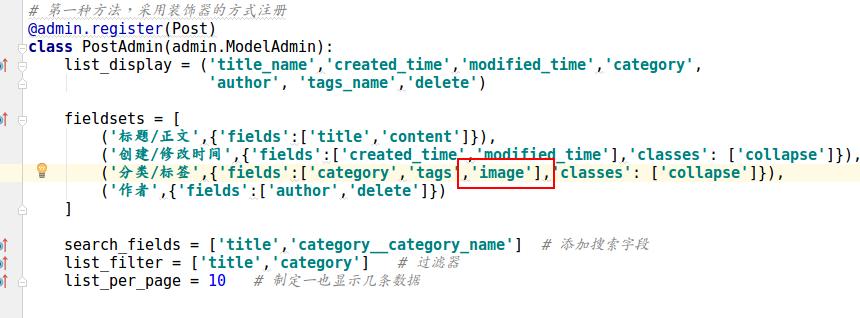
然后在admin.py中注册字段,让后台管理页面中能管理到这个字段。
设置图片保存路径,由于图片也是静态文件,所以我们同样将图片保存到静态文件目录/static/下 在配置文件setting.py下配置:
MEDIA_ROOT=os.path.join(BASE_DIR,"static/media") # 配置图片保存在static/media/目录下
MEDIA_URL = "/static/media/" # 访问图片路径,如果不设置,在admin后台中预览会找不到图片。
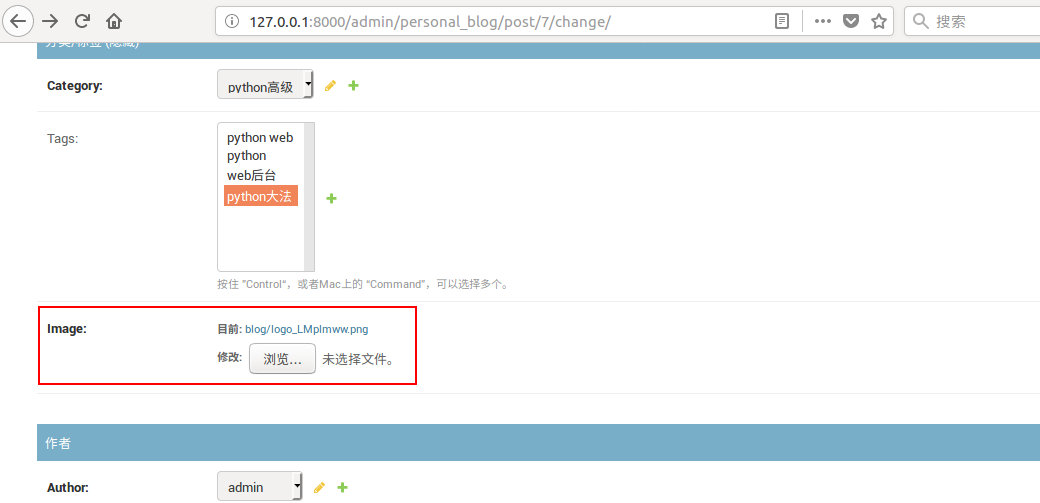
现在打开admin后台管理页面中post表,应该可以看到image图片字段了,点击浏览选择图片上传。
查看数据库,image字段中存的是图片的路径
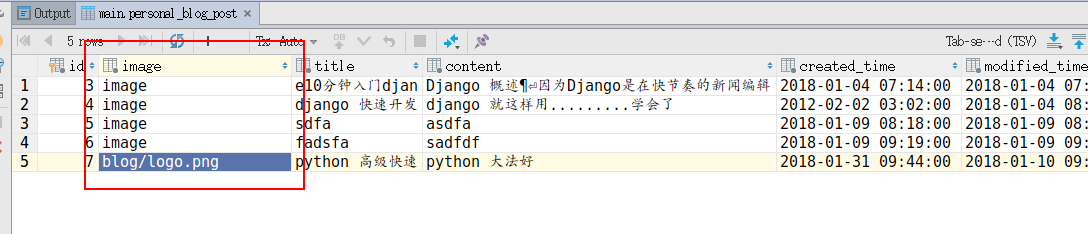
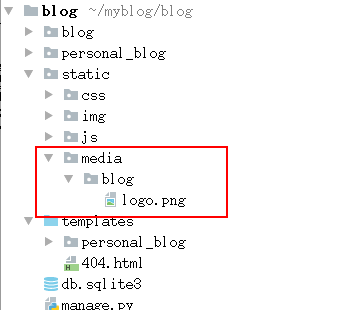
在/static/media/目录下自动创建了blog目录,并保存了刚才上传的文件。
2、自定义表单上传图片
在网站开发中,很多情况下都有图片上传的场景,比如 用户上传用户头像 等等。
创建模板定义表单上传图片 在模板中定义上传表单,要求如下: form 的属性enctype="multipart/form-data" 需要上传文件需要设置这个属性 form 的method为post,采用post请求方式, input 的类型为file,上传文件控件。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form method="post" action="/blog/pic_upload/" enctype="multipart/form-data">
<input type="file" name="pic">
<input type="submit" value="上传">
</form>
</body>
</html>
创建视图,get方法返回上传图片页面,Post方法接收用户上传的图片
django提供了保存文件的方法 FileSystemStorage 类,可以帮我们自动保存用户上传的文件。 FileSystemStorage 被定义在 from django.core.files.storage 中:
导入FileSystemStorage类
from django.core.files.storage import FileSystemStorage
视图
def pic_upload(request):
if request.method =='GET':
return render(request,'personal_blog/pic_upload.html')
elif request.method == 'POST':
pic = request.FILES.get('pic') HttpRequest 对象中的Files属性接收文件。以键值对的方式。
f2 = FileSystemStorage() # django自带的文件处理类,可以帮我们自动保存用户上传的文件。
path = f2.save('blog/%s' % (pic.name), pic) # 保存文件并返回文件名,如果文件名存在则会创建一个不重复的名称
# 将上传的图片路径保存在 标题为:'python 高级快速入门' 的文章。
p = Post.post_object.get(title='python 高级快速入门')
p.image = path
p.save()
return HttpResponse(pic.name)
配置url
url(r'^pic_upload/$', views.pic_upload),
访问: http://127.0.0.1:8000/blog/pic_upload/
点击浏览可以选择图片上传:
上传完成之后我们到admin后台管理页面中查看 标题为:'python 高级快速入门' 的文章。,image字段预览下图片,就是刚才上传的图片。
3、应用图片
上传到服务器的图片,数据库中只存了图片的地址,图片保存在了硬盘,这样如果模板中需要图片,跟我们之前处理静态文件的图片是一样的,只不过img标签中的src地址需要从数据库中取出。
先在admin后台管理页面中选择自己喜欢的图片上传,下面案例讲解怎么将图片应用到前端页面。
示例: 在post文章表中创建了图片字段,接下来我们将上传的图片应用到bolg首页。
在index.html首页模板中添加一个img标签,引入图片:
{% extends 'personal_blog/base.html' %}
{% block body %}
{% for p in post_list %}
<div class="forFlow">
<div class="day">
<div class="dayTitle">
<a>{{p.created_time}}</a>
</div>
<div class="postTitle">
<a class="" href="{% url 'detail' p.id %}">{{p.title}}</a>
</div>
<div class="postCon">
# 模板中使用 img 图片标签引入图片,src地址,保存在了post表中的image字段,所以将地址取出,拼接MEDIA_URL定义url地址。
<img width="200px" height="150px" src="/static/media/{{ p.image }}">
<div class="c_b_p_desc">摘要: {{p.content|wordwrap:2}} {# |slice 过滤器,只取前100个字符 #}
<a href="{% url 'detail' p.id %}" class="readmore">阅读全文</a>
</div>
</div>
<div class="clear"></div>
<div class="postDesc">posted @ 2018-01-06 19:51 地球守卫者 阅读(32) 评论(0)</div>
</div>
</div>
{%endfor%}
{% endblock body %}
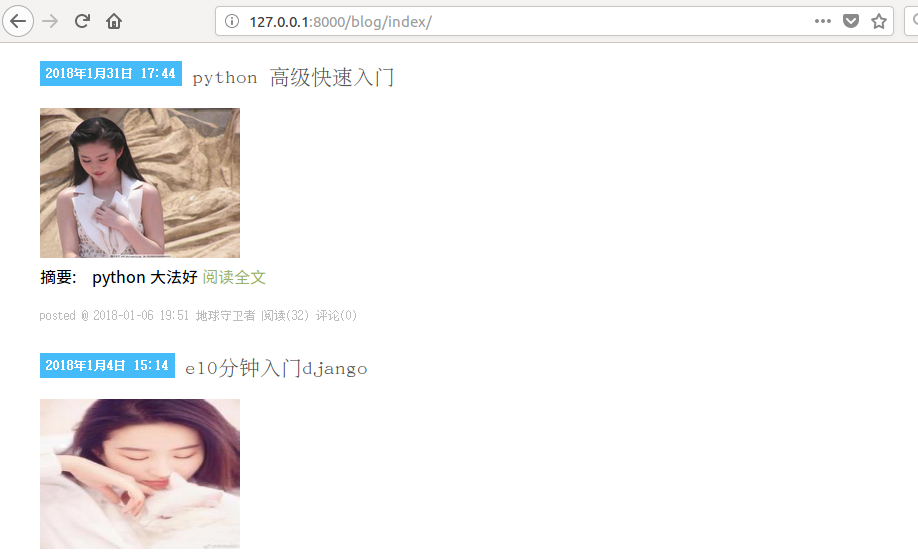
访问博客首页:可以看到上传的图片。
分页
1、分页方法
在网站开发中,一般列表页都是需要分页的,所以分页功能在网站开发中会经常使用,Django提供了一些类来帮助管理分页,这些类被定义在 django/core/paginator.py 中。
- 对象Paginator用于对列进行一页n条数据的分页运算
- 对象Page用于表示第m页的数据
Paginator接收一个列表或元组,Django的QuerySet对象,或者任何带有count()或len()方法的对象。当计算传入的对象所含对象的数量时,Paginator会首先尝试调用count(),接着如果传入的对象没有count()方法则回退调用 len()。这样会使类似于Django的QuerySet的对象使用更加高效的 count()方法,
Paginator对象所含属性和方法:
属性count:返回对象总数
属性num_pages:返回页面总数
属性page_range:返回页码列表,从1开始,例如[1, 2, 3, 4]
方法page(m):返回Page对象,表示第m页的数据,下标以1开始
Page对象
属性:
object_list:返回当前页对象的列表
number:返回当前是第几页,从1开始
paginator:当前页对应的Paginator对象
方法:
has_next():如果有下一页返回True
has_previous():如果有上一页返回True
has_other_pages 判断是否有上一页或者下一页
len():返回当前页面对象的个数
previous_page_number() 返回上一页码
next_page_number() 返回下一页码
Page对象是可迭代对象,访问每一个里面每一个对象。
2、案例
要使用django的分页对象需要先将Paginator导入
from django.core.paginator import Paginator
在django的shell环境下演示,打开django的shell环境
>>> # 这里表示对 list对象分页,每一页分配2个元素
>>> list = ['a','b','c','d']
>>> p = Paginator(list,2) # Paginator接收一个列表或元组,Django的QuerySet对象,或者任何带有count()或__len__()方法的对象。第二个参数是:每一页分配的元素数量
>>> p.count # 返回对象个数,
4
>>> p.num_pages # 返回总页数
2
>>> p.page_range #返回所有页码,这里分的是两页
range(1, 3)
Page对象
>>> p1.object_list # object_list 属性返回当前页的所有对象
['a', 'b', 'c']
>>> p1.number # 返回当前页的页码
1
>>> p1.has_next() # 判断是否还有下一页,有返回True,没有返回Flase
True
>>> p1.has_previous() # 判断是否还有上一页,有返回True,没有返回Flase ,当前在第一页,没有上一页,返回flase
False
>>> p1.next_page_number() #返回下一页页码。如果是最后一页,那么执行这个方法会报错,所结合has_next方法使用,先判断是否还有下一页。有则执行next_page_number方法,获取下一页的页码
2
>>> p1.previous_page_number() #返回上一页页码。如果当前在第一页执行会报 EmptyPage错误。
了解 paginator 和 page对象之后我们来看看实际开发中的应用:
将我们的博客首页做分页处理,先复制一份index.html的模板重命名为 paginator。
创建一个分页视图:
def paginator_index(request,index):
# 导入分页模块
from django.core.paginator import Paginator
# 查询所有文章
post = Post.post_object.all()
page = Paginator(post,2) # 对查询结果进行分页,每一页分2条数据
p = page.page(index) # 获取第一页的数据 ,index 是前端传过来的页码
return render(request,'personal_blog/paginator_index.html',context={'post_list':p})
配置url:
# 利用url参数给视图传页码
url(r'^paginator_index/(\d+)/$', views.paginator_index),
配置好url之后去访问刚才创建的视图: http://127.0.0.1:8000/blog/paginator_index/1/ url后面这个数字将提取作为页码传给视图,在浏览器中访问应该只有两篇博客文章,因为刚才在视图中分页的时候是2条数据分一页。
视图分好页需要在模板中将页码显示出来,修改 paginator_index.html 模板:
在模板中加入分页代码:
<ul style="list-style-type:none">
<li>
{% if post_list.has_previous %}
<a href="/blog/paginator_index/{{ post_list.previous_page_number }}/">
上一页
</a>
{% endif %}
{% for index in post_list.paginator.page_range %}
<a href="/blog/paginator_index/{{ index }}/">{{ index }}
</a>
{% endfor %}
{% if post_list.has_next %}
<a href="/blog/paginator_index/{{ post_list.next_page_number }}/">
下一页
</a>
{% endif %}
</li>
</ul>
改好模板之后重新刷新浏览器:
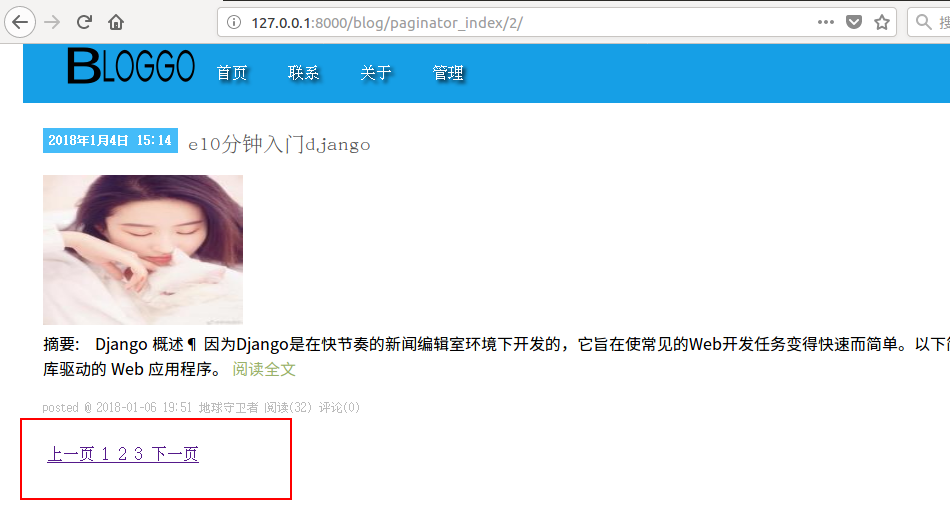
这里分页后没写css样式,只需要给html标签加css样式就会好看了。
仔细分析下分页代码,会发现上面的代码存在问题,那就是分页页码全部直接显示出来,要是有几十上百页全部显示出来显然不符合实际需求的。
需求:分页只显示当前页前后1页的页码。
如果要实现只显示当前页的附近几页,只要在迭代所有页码的时候做跟当前页进行判断是否在当前页左右1页中。如果是就显示,不是就不显示。
<ul style="list-style-type:none">
<li>
{% if post_list.has_previous %}
<a href="/blog/paginator_index/{{ post_list.previous_page_number }}/">
上一页
</a>
{% endif %}
{% for index in post_list.paginator.page_range %}
{# 这里判断是否符合 在当前页前后两页#}
{% if index > post_list.number|add:-2 and index < post_list.number|add:2 %}
<a href="/blog/paginator_index/{{ index }}/">{{ index }}
</a>
{% endif %}
{% endfor %}
{% if post_list.has_next %}
<a href="/blog/paginator_index/{{ post_list.next_page_number }}/">
下一页
</a>
{% endif %}
</li>
</ul>
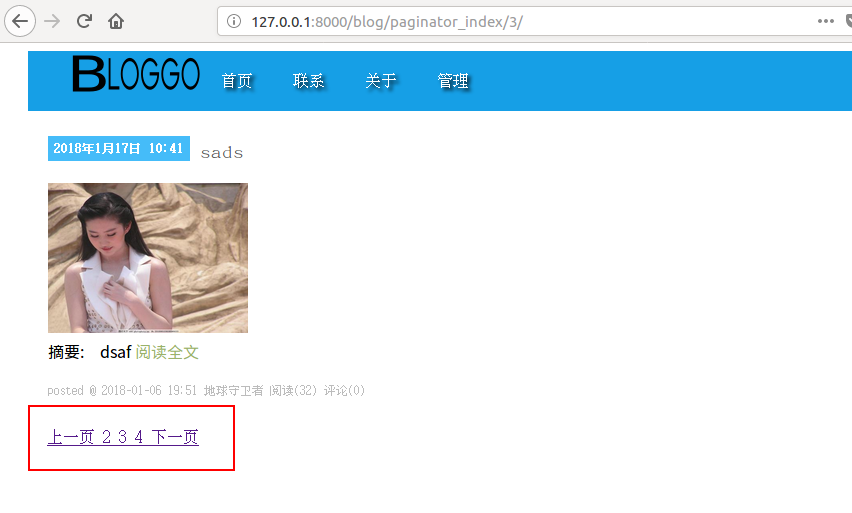
如果数据库中文章量比较少可能看不出效果,所以如果你的文章量少可以先添加多几篇文章。
重新访问可以看到已经实现我们所需要的效果,而不是像最开始那样全部页码显示出来。